100+ years of certification data, finally readable by software.
Underwriters Laboratories has been writing the rules of product safety since 1894. If something you've plugged in, worn, sat on, or driven through has a UL mark on it, somewhere there's a file describing exactly what's inside that product, who made the materials, and which UL standards every component meets. That archive is one of the most valuable safety datasets in the world. It's also, historically, written in the kind of long-form engineering prose that humans wrote for other humans, never expecting an algorithm would have to read it.
Here's the practical problem that creates. UL doesn't just certify finished products; it certifies the components and materials inside them. A power supply gets its UL listing partly on the strength of the plastic insulator inside it. A fuse mount inherits the certification of the tubing it's encased in. The whole certification ecosystem is a vast composition tree, and when a single node in that tree gets withdrawn, every product upstream of it can suddenly be out of compliance. The manufacturer might not even know.
UL did know, in theory. The data was right there in their files. But the files were unstructured, the components were referenced inconsistently, and tracing a withdrawn certification to every downstream product was a manual job that simply didn't get done in time. We built RISK so that it does.
The risk lived in the files. The files lived in PDFs. The PDFs lived in cabinets.
Decertification events aren't rare. A component supplier changes a formulation. A test result expires. A standard gets revised. Any of those can cause UL to withdraw a previously-issued certification. The work then is finding everyone who depends on that certification, before something downstream ships with a UL mark it no longer technically deserves.
For decades, that work was done by hand. UL account engineers knew their major manufacturers' product lines, kept mental notes about which components were used where, and chased down the chain whenever a withdrawal came through. It worked at a small scale. It absolutely did not work at the scale UL actually operates: tens of thousands of certified components, hundreds of thousands of finished products, and an archive of supporting documents that goes back to the era of typewriters and carbon paper.
The data itself was the heart of the problem. Component references inside a product file might appear as a free-text mention of a manufacturer and a part number, sometimes with a UL file number, sometimes without. One product file might reference its insulating tubing as "NORRES SCHLAUCHTECHNIK PVC 111, file E228503." Another might say "NORRES Wellflex tube." A third might just say "PVC tubing." All three could be the same component. None of those would match each other in a database query.
There was a second pain point too. Even when the technical match was found, not every match was actionable. A component certified under a related but distinct file. A product that used a different grade of the same material. A withdrawal that only affected a specific revision range. UL's account engineers needed software that could distinguish "real risk that needs a phone call" from "false positive that wastes everyone's time." Without that filter, any automated match list would be noise.
Read the corpus. Build the graph. Encode the rules. Show the reviewer only what matters.
RISK is four systems pretending to be one application. Each layer earns its place by solving a specific problem the layer above it couldn't. We built them in this order on purpose, because skipping a step always meant skipping a class of false positives.
Domain immersion before NLP
We spent the first weeks of the engagement embedded with UL's certification engineers and standards experts. The goal wasn't to learn how UL operates in the abstract. It was to understand exactly how a domain expert reads a product file: what they look at first, what they ignore, what makes them stop and reach for another reference document, what tells them a component reference is safe versus suspect.
That work seeded everything downstream. Our entity recognition models were trained on the patterns experts actually use, not on guesses about how product files are structured. The rules engine encoded the kinds of judgments those experts make every day. The reviewer worklist was laid out the way an account engineer would naturally scan it.
NLP that understands engineering prose
UL's product files are full of language that looks structured to a person and chaotic to a parser. Manufacturer names abbreviated three different ways. Material grades referenced by trade name in one paragraph and chemical composition in the next. UL file numbers buried inside parenthetical asides. We built an extraction pipeline that pulls component references, manufacturer entities, file numbers, and material identifiers out of 100+ years of free-form text, then resolves all the different ways the same component can be named into a single canonical reference.
The pipeline runs on Python with custom-trained spaCy models, supplemented by a rules-based normalization layer that handles the high-confidence patterns deterministically. Where the model is uncertain, the system surfaces ambiguous matches for human review rather than guessing. Wrong answers in product safety aren't an option, so silence is always preferable to a hallucinated match.
A composition graph that any node can walk upward from
Once we could reliably extract component references, we needed somewhere to put them. The data layer is a composition graph: end products at the top, component products beneath them, materials beneath those, certifying files attached to each node. Walk down the tree and you see what a product is made of. Walk up the tree and you see every product that depends on a given component or material.
Every withdrawal event becomes a graph traversal. The system takes the withdrawn file, walks upward through every product that references it, and produces a candidate impact set. That traversal happens in seconds across millions of relationships, which is the only way the rest of the system gets to feel responsive.
A rules engine UL can edit without us
A graph traversal will return everything. A reviewer can only act on what's actually risky. Sitting between the two is the rules engine, which encodes UL's expert judgment about what makes a candidate match a real risk. Standards version compatibility. Material grade equivalence. Geographic certification scope. Revision range applicability. The rules are written in a domain-specific language that UL's standards experts can read, edit, and version themselves, without filing a ticket or waiting on a developer.
That choice mattered more than any other in the project. UL's rules change as standards change, and a hard-coded rules layer would have decayed within a year. Putting the rules in the experts' hands meant the system could keep up with the regulatory landscape that fills it.
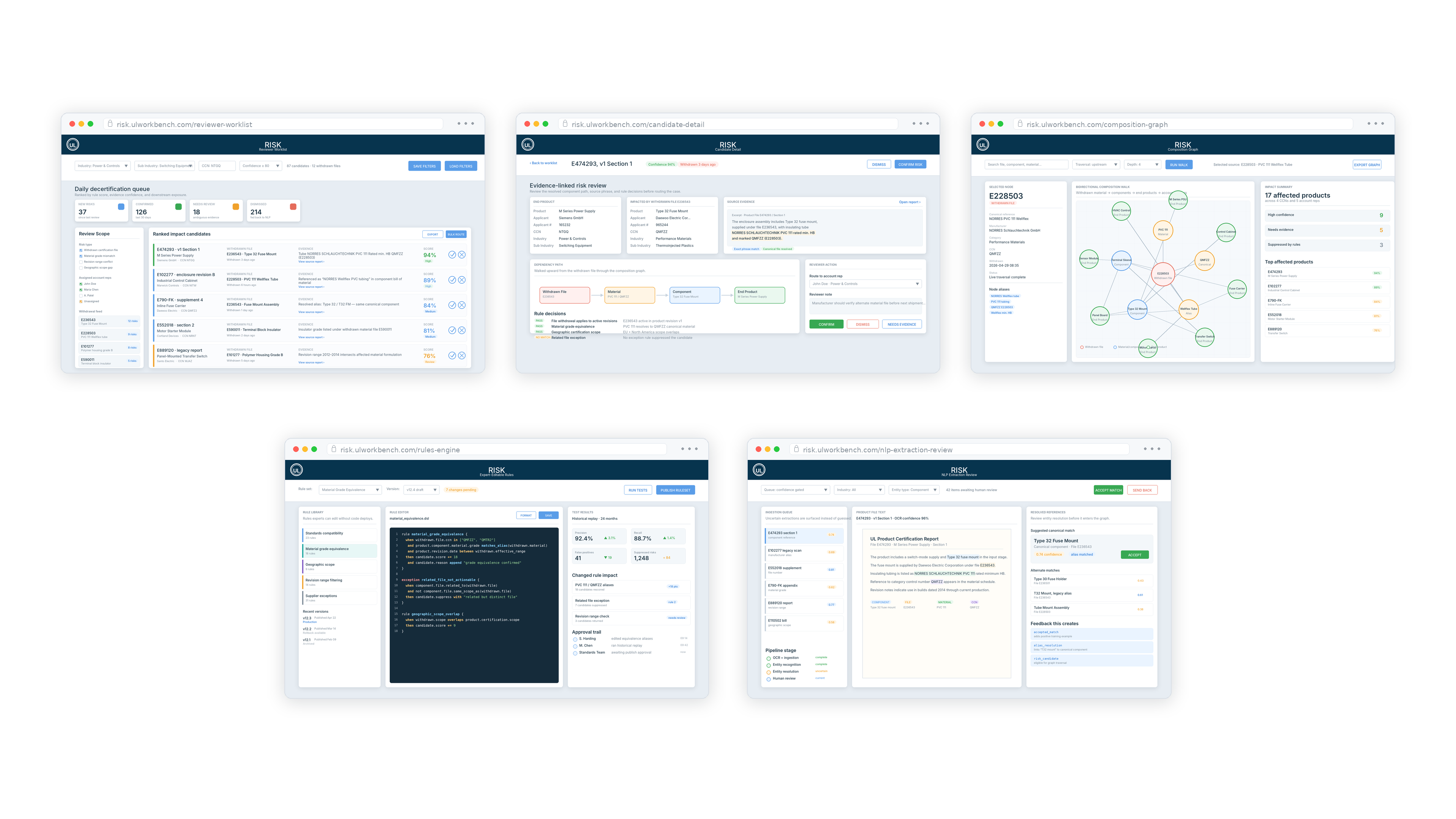
RISK platform architecture
Four layers, each handing a cleaner signal to the next. The corpus on the left is messy and historical. The worklist on the right is sharp, current, and actionable. Every layer in between exists to do that translation honestly, with humans reviewing whatever the machines aren't sure of.
A reviewer worklist over a 100+ year old corpus.
RISK gives a UL account engineer one screen to live in: a worklist of products that may have just lost a piece of their certification, ranked by a confidence score the rules engine produced, with the supporting evidence one click away. Confirm. Dismiss. Move to the next one. The system does the searching; the engineer does the judging.
Industry filtering that matches how UL is organized
Account engineers don't cover all of UL's certification universe; they cover a slice. The worklist filters by industry, sub-industry, and CCN (Category Control Number), so a reviewer working power and controls only sees risks affecting power and controls. Saved filters carry across sessions, and the same view holds whether there are five candidate matches or five hundred.
Evidence in line, not in a different system
Each row shows the affected end product, the withdrawn file driving the risk, and the evidence the system used to make the connection: the exact phrase from the product file, the resolved canonical reference, and a link to the original source document. A reviewer never has to leave the worklist to verify what they're looking at, which is the difference between a tool people use and a tool people avoid.
Confirm, dismiss, and a feedback loop the models actually learn from
Every confirm or dismiss action becomes a labeled training example. Over time, the NLP pipeline gets better at recognizing the patterns that lead to true positives and quieter on the patterns that don't. UL's domain experts effectively teach the system as they work, and they don't have to do anything special to make that happen.
A rules engine that keeps up with the regulations
UL's standards experts can edit, version, and roll back the rules without a code deployment. When a standard is revised, the rule that encodes that standard's compatibility logic is changed in the rules editor, tested against historical data, and put into production the same day. The application code doesn't need to know.
UL got out ahead of decertification, instead of cleaning up after it.
RISK shipped to UL's account engineering teams and changed the cadence of how decertification gets handled. The risks that used to surface weeks after the fact, sometimes through a manufacturer's own customer complaint, now surface within hours of the withdrawal event.
The deeper change was upstream of the worklist. UL's account engineers now have a defensible, evidence-linked picture of which products are exposed to a withdrawal the moment it happens, and they get to a manufacturer with that picture before the manufacturer's own quality team has finished their morning standup. That's a different relationship than UL had with its clients before. The certification body becomes the early-warning system, not the after-the-fact auditor.
The platform also surfaced a class of insights nobody had asked for. Once the composition graph existed, UL could answer questions it had never been able to answer before: which suppliers have the highest concentration of downstream products dependent on them, which materials show up across the most CCNs, where the structural risks in the certification ecosystem actually live. That's the kind of strategic visibility that justifies a data platform's existence well past the original use case.